集群分析 (Clustering analysis) 為統計方法中在處理多變量資料時,將資料簡化分類的一種方法,以計算 “距離" 的方式將距離較近的資料分類在一起,分類在一起的資料也有性質接近的意義,使用的方法可以分別為,分層法 (Hierarchical) 與非分層法 (Nonhierarchical)。同時集群分析也是機器學習 (Machine learning) 中的非監督式學習 (Unsupervised learning)。今天要介紹期群分析方法並在 R 上如何實作。
分層法 (Hierarchical)
分層法中先將每筆資料當成一個群體,在透過定義的距離將距離接近的資料排序,將任兩筆最接近的資料分類成同一群,然後將任三筆最接近的資料分類成同一群,重複這個動作直到全部的資料分成同一群。使用的距離定義如下:
- 歐式距離 (Euclidean distance):
- 曼哈頓距離 (Manhanttan distance):
- 坎培拉距離 (Canberra distance):



會有這麼多計算距離的方式是有原因的,因為不同的計算距離方式會導致不同的分群結果,根據不同的資料型態,選擇不同的距離計算方法才是正確的作法。有了資料之間的距離後,就可以依據距離分類資料,分類方式如下:
- 單一連結法 (Single Linkage):
- 完全連結法 (Complete Linkage):
- 平均法 (Average Linkage):
- 中心法 (Centroid Method):




根據分類演算法就可以得到階層式的集群分析結果,可以以樹狀圖呈現分類狀況。到目前沒有一種方法特別有顯著有效,在不同資料的型態下不同的方法有不同的表現。
非分層法 (Nonhierarchical)
K-means 分析法就是所謂的非分層法,將資料分成 K 群,並且使得 (1)群內變異最小;(2)群間變異最大。
R 實作
install.packages("apcluster") library(apcluster) ## create two Gaussian clouds cl1 <- cbind(rnorm(100,0.2,0.05),rnorm(100,0.8,0.06)) cl2 <- cbind(rnorm(50,0.7,0.08),rnorm(50,0.3,0.05)) x <- rbind(cl1,cl2) plot(x, xlab="",ylab="")
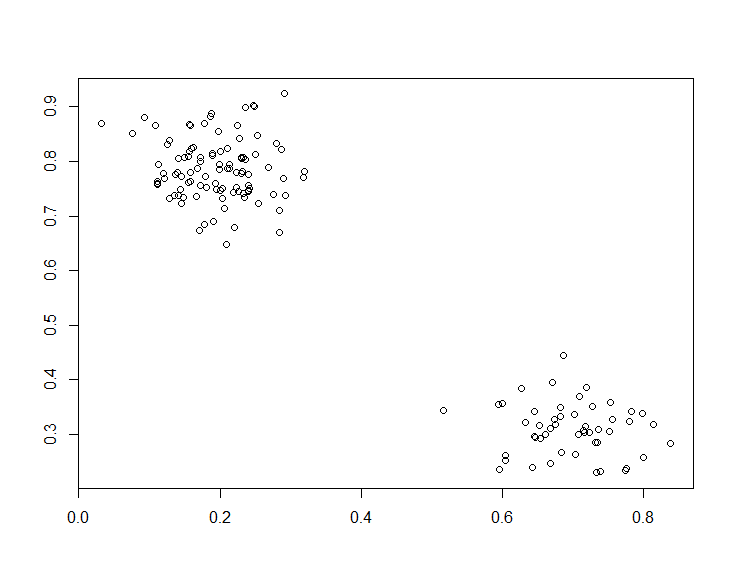
首先我們創造假資料 x ,並且透過分佈圖我們可以用眼睛判斷大概是分成兩資不同的資料群。
## compute similarity matrix (negative squared Euclidean) sim <- negDistMat(x, r=2) agg <- aggExCluster(negDistMat(r=2),x) plot(agg)

cl1a <- cutree(agg2, k=2) plot(cl1a,x)

透過數狀圖我們可以瞭解,資料大概可以分成兩群或四群。這個圖為以 K-means = 2,將資料分成兩群後繪圖的結果。
結論
集群分析 (Clustering analysis) 提供我們在做分析多變量資料時,快速且值覺得分類方式將資料分群。然而方法眾多遠遠多於上述的方法,像是沒有介紹到的 SOM 方法。同樣的依照資料的型態挑選分析的方法才是最好的做法。
